TMU’s Chang analyzes social media metrics, impacts
Source: TMU Graduate Institute of Data Science/Bachelor Program in Data Science and Management
Published on 2018-12-23
After joining Academia Sinica in 2008, TMU Associate Professor Yung-Chun Chang carried out nearly a decade of research in the Physics and Information Science institutes, receiving a doctorate in information management from National Taiwan University based on this work. He began teaching data science and management at TMU in 2017 in the Graduate Institute of Data Science.
Dr. Chang’s interests include exploration of texts, natural language processing, conversational response robots and related machine learning and language recognition technologies. His recent research focuses on combining expression of syntactic knowledge and machine learning to create robots that can carry out complex conversations. Dr. Chang’s other recent interest is developing an automated text classification structure that can serve a wide range of applications including emotional analysis, theme detection or answer and response systems.

Dr. Yung-Chun Chang
New directions for Chang’s team include analyzing readers’ emotions generated by short social media texts and then organizing these results into descriptions of public opinions and perceptions. The team has proposed “public opinion keyword embedding” (POKE) to represent each short text from social media. Their results showed this research method was able to effectively express public opinion meanings for each short text, and used this to depict and describe public opinion in social media. Their results were analyzed travelers’ opinions on the TripAdvisor website, using emotion analysis of recommendations made to hotels in terms of their operating strategies. The team’s results were published[1] in international scholarly journals.
The lack of a commercially available comprehensive Chinese pre-processing tool makes processing of natural Chinese language problematic. Dr. Chang’s team is working with Academia Sinica’s Intelligent Agent System Lab (IASL) to develop a multi-objective Chinese pre-processing system currently known as the Multi-Objective NER POS Annotator or Monpa.

Monpa’s operational interface
Monpa (http://monpa.iis.sinica.edu.tw:9000/chunk) is a multi-tasking tagging method based on bidirectional recurrent neural networks that is able to simultaneously carry out segmentation and part-of-speech tagging as well as named entity recognition. Monpa helps obtain basic vocabulary information as well as specialized terms and information (names of individuals, places and organizations) to assist in extracting keywords. The team intends to share its results with the public to help Chinese users and address related technological gaps facing industry.
[1] Social media analytics: Extracting and visualizing Hilton hotel ratings and reviews from TripAdvisor. 2017, IF 3.872﹝SCI, SSCI﹞, categories 7% in INFORMATION SCIENCE & LIBRARY SCIENCE
 https://oge.tmu.edu.tw/wp-content/uploads/2024/04/olympiad-poster-2.jpg
909
640
gps
/wp-content/uploads/2018/05/02-紅logo並置.png
gps2024-04-19 16:36:372024-04-19 16:38:14International Histology Olympiad at the Mongolian National University of Medical Sciences (MNUMS)
https://oge.tmu.edu.tw/wp-content/uploads/2024/04/olympiad-poster-2.jpg
909
640
gps
/wp-content/uploads/2018/05/02-紅logo並置.png
gps2024-04-19 16:36:372024-04-19 16:38:14International Histology Olympiad at the Mongolian National University of Medical Sciences (MNUMS) https://oge.tmu.edu.tw/wp-content/uploads/2023/07/20230321台北醫學大學校園形象攝影-1-scaled.jpg
1000
1500
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-19 16:08:552024-04-21 06:23:53[Open Application] Fall 2024 TMU admission for applicants seeking the MOFA Taiwan scholarship
https://oge.tmu.edu.tw/wp-content/uploads/2023/07/20230321台北醫學大學校園形象攝影-1-scaled.jpg
1000
1500
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-19 16:08:552024-04-21 06:23:53[Open Application] Fall 2024 TMU admission for applicants seeking the MOFA Taiwan scholarship https://oge.tmu.edu.tw/wp-content/uploads/2024/04/1712888393174-scaled.jpg
1125
1500
gps
/wp-content/uploads/2018/05/02-紅logo並置.png
gps2024-04-15 16:31:512024-04-16 10:48:20Outward visit_2024 Asia Pacific Association of International Education (APAIE) conference and exhibition
https://oge.tmu.edu.tw/wp-content/uploads/2024/04/1712888393174-scaled.jpg
1125
1500
gps
/wp-content/uploads/2018/05/02-紅logo並置.png
gps2024-04-15 16:31:512024-04-16 10:48:20Outward visit_2024 Asia Pacific Association of International Education (APAIE) conference and exhibition https://oge.tmu.edu.tw/wp-content/uploads/2024/04/for-OGEW.jpg
788
940
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-12 12:05:012024-04-17 18:23:122024 TMU European Culture Festival
https://oge.tmu.edu.tw/wp-content/uploads/2024/04/for-OGEW.jpg
788
940
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-12 12:05:012024-04-17 18:23:122024 TMU European Culture Festival https://oge.tmu.edu.tw/wp-content/uploads/2024/04/shutterstock_1629801502.jpg
667
1000
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-10 17:42:292024-04-10 17:42:293 PhD programmes to get excited about
https://oge.tmu.edu.tw/wp-content/uploads/2024/04/shutterstock_1629801502.jpg
667
1000
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-10 17:42:292024-04-10 17:42:293 PhD programmes to get excited about https://oge.tmu.edu.tw/wp-content/uploads/2024/04/airmeet_da312f7f-4dfc-4912-8881-d0e302991d63.jpg
810
1440
gps
/wp-content/uploads/2018/05/02-紅logo並置.png
gps2024-04-09 15:00:432024-04-09 15:10:46Career Networking Event – working in Hungary
https://oge.tmu.edu.tw/wp-content/uploads/2024/04/airmeet_da312f7f-4dfc-4912-8881-d0e302991d63.jpg
810
1440
gps
/wp-content/uploads/2018/05/02-紅logo並置.png
gps2024-04-09 15:00:432024-04-09 15:10:46Career Networking Event – working in Hungary https://oge.tmu.edu.tw/wp-content/uploads/2024/03/骨科新創獎團隊合成-scaled.jpg
979
1500
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-03 09:00:252024-03-29 15:03:31TMU Healthcare System Develops Outstanding Innovative Medical Devices, Advancing AI Healthcare
https://oge.tmu.edu.tw/wp-content/uploads/2024/03/骨科新創獎團隊合成-scaled.jpg
979
1500
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-03 09:00:252024-03-29 15:03:31TMU Healthcare System Develops Outstanding Innovative Medical Devices, Advancing AI Healthcare https://oge.tmu.edu.tw/wp-content/uploads/2024/03/feature-imageB074012-scaled.jpg
924
1500
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-02 09:00:322024-03-29 15:02:47Preserving History and Building Sustainability: The Renovation of TMU Teaching Building
https://oge.tmu.edu.tw/wp-content/uploads/2024/03/feature-imageB074012-scaled.jpg
924
1500
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-04-02 09:00:322024-03-29 15:02:47Preserving History and Building Sustainability: The Renovation of TMU Teaching Building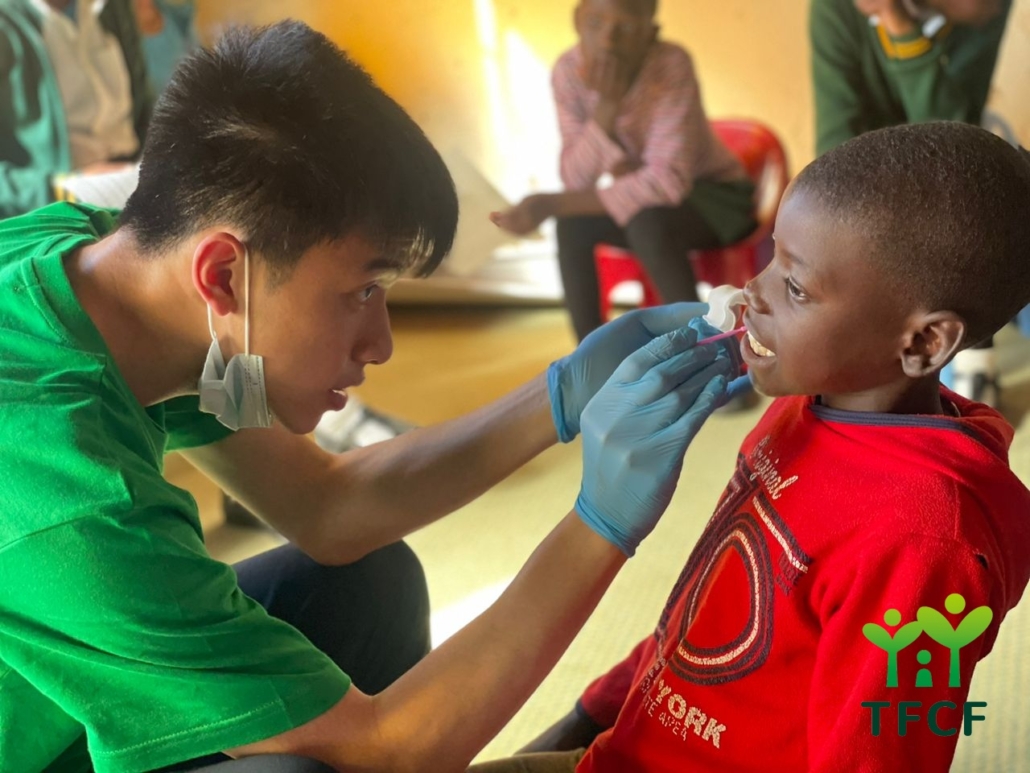 https://oge.tmu.edu.tw/wp-content/uploads/2024/03/史瓦新聞.jpg
960
1280
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-03-28 09:00:182024-03-29 15:04:04TMU Students’ Overseas Volunteer Efforts Recognized by Taiwan’s Youth Development Administration
https://oge.tmu.edu.tw/wp-content/uploads/2024/03/史瓦新聞.jpg
960
1280
global.initiatives
/wp-content/uploads/2018/05/02-紅logo並置.png
global.initiatives2024-03-28 09:00:182024-03-29 15:04:04TMU Students’ Overseas Volunteer Efforts Recognized by Taiwan’s Youth Development Administration